Developer Guide
General
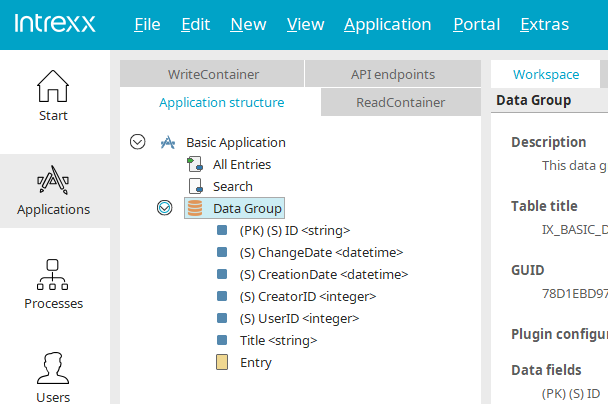
Namespace for applications
The namespace for the application should be used for naming data groups, request parameters and session parameters. The namespace can be a company name or a combination of the company and application. This is the greatest challenge because with a large amount of partners and applications, it is very likely that names will overlap.
Make a list of at least the used request parameters and the possible values in the application handbook. This is important if you want to safeguard the application with request value validators in the portal.
Data groups
-
the maximum length of the table name should be 26 characters
-
as descriptive as possible (e.g. SHARE_FEED)
-
In the singular form
-
In English
-
In block capitals
Intrexx data groups
Intrexx data groups automatically receive the name "XDATAGROUP" followed by a random key to avoid a name being given twice.
File data groups
When creating a file data field, a child data group is created automatically. The data groups receive the label "XFILEDATAGROUP" followed by a random key. Name these groups with the same logic as the standard data groups.
System data groups
System data groups should be named in the same way as Intrexx data groups. Their name should always end with "SETTING".
External data groups
External data groups connected to Intrexx standard data groups (e.g. DSUSER, DSOBJECT, etc.) or the application's own data groups do not need to be renamed.
It should however be noted that there are no database-specific prefixes in the data group definition (dbo.<data group name>) but rather just the data group name in block capitals.
Data fields
The appropriate naming of data fields is also important if applications are modified or expanded later and if accesses are executed via SQL statements in Velocity or Groovy. The legibility and also the internal use of the application play a role here.
Field names
The data fields generated by Intrexx receive a type key to begin with followed by the title which was entered while the field, or also the corresponding element, was created (e.g. "STR_TITLE_6A585D30"). Here, umlauts will be transformed and the field name is shortened to 30 characters if necessary. Field names should be defined as follows to avoid using SQL keywords and to achieve an optimal legibility:
-
maximum length of the column name should be 30 characters
-
as descriptive a name as possible
-
Must begin with the type key of the data field type (e.g. STR_NAME, B_IS_VISIBLE, …)
-
In English
-
In block capitals
Here is an overview of the prefixes:
-
String: STR
-
Boolean: B
-
Float and currency: FLT
-
Longtext: TXT
-
Date, Time, Date and Time: DT
-
File: FILE
Primary key
The data type of the primary key can either be an integer value or a GUID. Preferably, this should be used because the GUID has multiple advantages over an integer:
-
A GUID protects against the data record ID being guessed. Integer values can be guessed using incrementing.
-
Creating a new data record does not require the new ID to be identified.
-
There are no gaps in the IDs. When deleting data records with integer values, gaps are created.
-
When merging or copying data with GUIDs, IDs do not need to be identified. The effort required and errors are reduced when using GUIDs, in comparison to integer values - And the code is leaner.
References
In Intrexx, reference data fields automatically receive the prefix "REF_" followed by a random key. The name can be adjusted before the application is published for the first time on the Expert tab in the reference properties. Show the data fields in the application structure by selecting "Show data fields" from the Edit menu while the corresponding data field is selected.
Index
To optimize performance, indices should be recorded for data fields that are searched through regularly or are used for sorting. The index name may not be longer than 18 characters and should be constructed based on the following schema: IX_<DG-Key>_<Counter>, e.g. IX_SHAREFEED_1.
Naming elements
To keep names in the Application Designer as uniform as possible, certain rules should be considered here. Principally, the following applies: give as many elements as possible a corresponding name and do not keep the default presets.
View pages
The page names are currently also the displayed name in the browser (e.g. in the breadcrumb path, tooltip title, etc.). For that reason, the titles for development cannot be separated from the displayed titles. However, certain view pages used for specific cases are an exception to this:
-
View pages for free layout tables: _tblPageName
-
View pages for mobile free layout tables: _mTblPageName
-
View pages for sending emails: _emailPageName
-
View pages for Share feed plugins: _sharePageName
-
View pages for mobile Share feed plugins: _mSharePageName
-
View pages for generating PDFs: _pdfPageName
-
Mobile pages: _mPageName
-
View pages for search results: _searchPageName
Groupings
As groupings are often also shown and hidden via JavaScript, they should be given descriptive names according to the following scheme: _grpGroupName. The group name should be specified in English.
Naming conventions
INTREXX Ltd Quality Assurance performs automated application tests. Here, the application structure, programming code (JavaScript, Groovy, Velocity) and layout will be checked as to whether they meet certain requirements. The following names are part of this:
|
Test type |
Test |
Comments |
|---|---|---|
|
Names |
|
Naming with hyphen, such as e-mail, is not allowed. This refers to labels – not the data fields themselves. |
|
Table length |
The compliance to the maximum length for the table name |
|
|
Table column |
Size |
The compliance to the maximum length for the column name |
|
Column name |
LID |
Data type may only be integer |
|
Column name |
FKLID |
Data type may only be integer |
|
Column name |
STRID |
Data type may only be string |
|
Column name |
FKSTRID |
Data type may only be string |
Permissions
The permissions required for the application may only be defined using groups. The groups have to be in English and according to the following pattern:
Application.<application name>.<role>
The following foundational permission objects appear in many applications:
|
User group |
Description |
|---|---|
|
Application.<Applikationsname>.User |
Normal user of the application |
|
Application.<Applikationsname>.Administrator |
Administrator of the application who manages settings and master data |
|
Application.<Applikationsname>.Manager |
Users who, for example, are responsible for editing tasks in an application |
|
Application.<Applikationsname>.Approver |
Validators and/or approvers if the application has a corresponding workflow |
|
Application.<Applikationsname>.Reviewer |
Auditors and/or people who provide feedback regarding a procedure |
|
Application.<Applikationsname>.Responsible |
Responsible person, such as department leaders, who are given access to the data from their department |
The "Users" user group should not be used to keep the permission control flexible. If required, the role should be mapped in the portal to the user role in the application. Special permission objects can be defined depending on the application. The implemented permission objects and their function must be documented in the application's handbook as depicted in the table above. To limit the selection of users in a context-related manner, a special filter is available; this should be documented with the defined permission groups. The selection of users via the UserID is limited when using "Is contained in" with the system value "Set and containing sets". What is important with this filter variation is that inheritance is also taken into account.
Script
The programming code delivered with the application should be done in a style that's as uniform as possible. This means that the methods, function names, variables and comments should be created
-
In English
-
with correct grammar and spelling
-
with uniform syntax
-
in correct CamelCase
JavaScript coding conventions
If possible, the use of JavaScript should be avoided as much as possible. Conditional display of groupings and buttons with server-side Velocity code is more secure and furthermore, supports barrier-free requirements.
Error handling
In some error handling cases, the Intrexx notifier function is needed to provide the user with feedback – this helps maintain a uniform standard.
Notifier.status.notify("No date was specified.", "Note");
Notifier.status.error("The entered cost center does not exist.", "Error");
Velocity coding conventions
Security
Among other things, entire HTML constructions, can be created with Velocity. If errors occur, this can hinder an entire page being loaded or even the portal itself. Additionally, information can be provided using Velocity templates for which the user does not have permission, according to the Intrexx framework. For that reason, Velocity templates must be checked well and errors intercepted.
If you use your own Velocity files in applications which, for example, perform your own SQL requests and therefore circumvent the usual permissions structure of the Intrexx business logic, the authorized use of the Velocity code should be checked. If this check is not performed, the file can simply be called up using the browser and the content can be displayed without a permissions check. This problem is similar to that of an SQL injection. User entries are applied without verification and forwarded to API functions; this should be prevented. Your code should be enclosed by the following construct to guarantee the server-side verification:
#if($AccessController.hasPagePermission("APP_GUID", "PAGE_GUID", "access"))
## Your Code ##
#end
The GUID of the target application is entered as the first parameter, the GUID of the target page as the second. As the third parameter, the key "access" is entered. The parameters should be specifically entered into the call. The transfer in the form of request values makes the verification more dynamic but makes you more susceptible to attack. If access to a data group should be verified using Velocity (before the database is accessed), the following construct can be placed around the function:
#if($AccessController.hasDatagroupPermission($ProcessingContext,"APP_GUID", "DATAGROUP_GUID", "read"))
## Your Code ##
#end
The processing context is transferred using the first parameter. The GUID of the target application is specified as the second parameter, the GUID of the data group as the third. As the fourth parameter, one of the following keys should be entered:
|
Key |
Function |
|---|---|
|
create |
Create |
|
delete |
Delete |
|
delete-own |
Delete own data |
|
read |
Read |
|
read-own |
Read own data |
|
write |
Change |
|
write-own |
Edit own data |
The parameters should be specifically entered into the call. The transfer in the form of request values makes the verification more dynamic but makes you more susceptible to attack.
Velocity includes
Velocity files should always be included in the application package to ensure that installation is straightforward. If you are using overarching Velocity templates, these are to be stored in the portal directory internal/system/vm/html/include in their own subdirectory. All other directories are reserved for Intrexx.
Groovy coding conventions
Documenting codes
The codes in JavaScript, Velocity or Groovy should be documented in detail. Primarily, this means that meaningful comments should be implemented into the code to make its function apparent. Use the option to implement JSDOC comments as well.
Prepared query
The correct use of PreparedQuery for performing SQL statements in Groovy and Velocity prevents an attack via SQL injection. An important prerequisite for this is knowledge regarding the affects and influences of parameters that are entered into the SQL statement. Intrexx provides an abundance of functions for using PreparedQuery. That being said, using it incorrectly can create holes, which should be avoided. In Groovy, a correct PreparedQuery is shown below. It's important that the values in the WHERE clause are defined using the placeholder "?" and then set using set methods. The respective set methods guarantee that the expected format is inserted. This means that if a character string is smuggled in instead of an integer, then this will not be processed and causes an error. The detailed error message must be suppressed in the portal so that the full effect unfolds.
def conn = g_dbConnections.systemConnection
def stmtUpdate
def stmt = g_dbQuery.prepare(conn, "SELECT LID FROM DSUSER")
def rs = stmt.executeQuery()
while (rs.next())
{
stmtUpdate = g_dbQuery.prepare(conn, "UPDATE DSUSER SET ... WHERE LID = ?'")
stmtUpdate.setInt(1, rs.getIntValue(1))
stmtUpdate.executeUpdate()
stmtUpdate.close()
}
rs.close()
stmt.close()
The following construct is defined incorrectly and involves a high risk.
def conn = g_dbConnections.systemConnection
def l_UserId = g_record["GUID"].value
def stmt = g_dbQuery.prepare(conn, "SELECT DTBIRTH FROM DSUSER WHERE LID = '${l_UserId}'")
def rs = stmt.executeQuery()
while (rs.next())
{
rs.getDateValue(1)
}
rs.close()
stmt.close()
The value from the data field can be manipulated by a hacker and instead of the expected LID, a character string with the expansion of the "WHERE" request can be smuggled in.
Expected:
WHERE LID = 10
Manipulated:
WHERE LID = 10 OR LID > 0
With this change, the hacker receives all database entries in the user database. If the request values are additionally checked using validators, character strings via request values which should return integer values, for example, cannot get so far that they are inserted into the statement. Another very critical construction is shown below. The SQL statement is formed by merging a character string and a variable. In this case as well, the variable, which is additionally transferred via a request value, can be abused to expand the "WHERE" clause.
def l_request = g_request.get("rq_myparameter")
def l_sql = "SELECT DTBIRTH FROM DSUSER WHERE LID = "l_sql += l_request
def stmt = g_dbQuery.prepare(conn, l_sql)
def rs = stmt.executeQuery()
...
The same conditions apply in the Velocity environment. The PreparedQuery must also be used correctly here:
#set($UserId = $DC.getValueHolder("GUID").getValue())
#set($stmt = $PreparedQuery.prepare($DbConnection,
"SELECT DTBIRTH FROM DSUSER WHERE LID = ?"))
$stmt.setInt(1, $UserId)
#set($rs = $stmt.executeQuery())
#foreach($element in $rs)
$element.getDateValue(1)
#end
$rs.close()
$statement.close()
An equally critical construction is the definition of a query which is used to enter the data field name dynamically. Especially if the field names are determined by data from the request or other external sources. This applies to Groovy and Velocity.
def ergebnis = g_dbQuery.executeAndGetScalarIntValue(conn,
"SELECT count(*) FROM DATAGROUP WHERE LID = ? AND $FIELDNAME1 IS NOT NULL AND $FIELDNAME <> ''",0)
A lot of security levels need to envisaged for such a solution. The ideal solution is to avoid such constructions altogether. The following security policies would be advised:
-
The client sends random unique key values for the individual fields to the server. The key values can, for example, be the GUIDs of data field names or query string parameters.
-
Using corresponding validators, the transferred values will be checked in advance (e.g. whitelist). If a correspondence is not found, the server-side processing will not be executed.
-
The server checks whether the logged in user has the necessary permissions to perform the following code (usually read access to the data group).
-
The server searches in a list of allowed field GUIDs. If it finds a parameter that is not found, it either brings up an exception or ignores the parameter - depending on the requirements.
-
Based on the field GUIDs, the corresponding column names in the database will be identified and a prepared statement will be constructed.
-
The current values are transferred to the prepared statement.
-
The database request is performed
Multilingual applications
All information on this topic can be found here.
Clonable applications
So that an application can be cloned, the Groovy and Velocity scripts in particular must be defined correctly. This particularly applies to the data groups and SQL statements. When cloning/duplicating an application, Intrexx reassigns all of the GUIDs and with that, adjusts the GUIDs in the scripts (Groovy, Velocity, JavaScript) accordingly, so that everything continues to work together. For this reason, the data group definitions must always be made using the data group's GUID:
def l_strIsoLanguage = it
def l_intLanguageDetect = g_dbQuery.executeAndGetScalarValue(conn,
"SELECT COUNT(*) FROM DATAGROUP('98C0EC3CC539925C8B7644F4AB726BE2F38038F1')
WHERE LANG = ?", 0) {
setString(1, l_strIsoLanguage)
}
#set($stmtFloors = $PreparedQuery.prepare($DbConnection,
"SELECT T0.STRID, T1.STRNAME, T1.STRSHORTNAME FROM
DATAGROUP('B1156946E0CF3215576D4595A757A3FD0BB31C22') T0 LEFT OUTER JOIN
DATAGROUP('1037FA883B005B35FE5D4B8A10645B9FB2B04933') T1 ON ((T0.REF_PROPERTY
= T1.PROPID) AND (T1.LANG = ?)) WHERE T0.STRPARENTID = ? AND T0.REF_CLASS = ?
ORDER BY T1.LSORT"))
$stmtFloors.setString(1, $lang)
$stmtFloors.setString(2, $Builiding)
$stmtFloors.setString(3, "LEVEL")
#set($rsFloors = $stmtFloors.executeQuery())
GUIDs should also be used when accessing data fields on application pages in the Velocity context. For this, the key "page.requiredDataFields.mode" with the value "all" must be set in the Settings of each page (The quickest method to provide all of the data group's data fields via GUIDs). This is also the basis for the access in the Velocity templates from the previous section.
In the Velocity context, the saved data can be accessed with the following method:
$DC.getValueHolder("GUID_DATA_FIELD").getValue()
## When page is used in a free table
$drRecord.getValueHolder("GUID_DATA_FIELD").getValue()
The advantage of this method is that the information does not need to be physically positioned on the page as a view field (or where applicable, hidden).
Portable applications (databases)
Because various databases can be implemented for use with Intrexx, the SQL statements should be defined as neutrally as possible. This means that database-specific functions should not be used. The ANSI SQL standard is to be upheld here. If there are not any neutral alternatives for an SQL statement, a database switching point must be defined for the SQL statement; this uses the appropriate statement for each database.
Switching point for Groovy:
def conn = g_dbConnections.systemConnection
switch (conn.descriptor.databaseType)
{
case "Db2":
// DB2
break
case "Derby":
// Derby/Java DB
break
case "Firebird":
// Firebird
break
case "HSQLDB":
// HSQLDB
break
case "Ingres":
// Ingres
break
case "Oracle8":
// Oracle 8
break
case "Oracle9":
// Oracle 9
break
case "Oracle10":
// Oracle 10
break
case "Oracle11":
// Oracle 11
break
case "Oracle12":
// Oracle 12
break
case "PostgreSQL":
// PostgreSQL
break
case "MaxDB":
// MaxDB
break
case "MsSqlServer":
// Microsoft SQL Server
break
case "Standard":
// unspecified
break
default:
assert false : "Unexpected database type."
break
}
Switching point for Velocity:
#set($DbName =
$DbUtil.getConnection("IxSysDb").getDescriptor().getDatabaseType())
#if($DbName == "MsSqlServer")
#set($sql = " SELECT TOP 10 * FROM MyTable ORDER BY LID DESC")
#elseif($DbName == "PostgreSQL")
#set($sql = "SELECT * FROM MyTable ORDER BY LID DESC LIMIT 10")
#elseif($DbName == " Oracle9" || $DbName == " Oracle8")
#set($sql = " SELECT * FROM (SELECT * FROM MyTable ORDER BY LID DESC)
WHERE rownum <= 10")
#else
$Debug.info("Unexpected database type")
#end
Processes
The following should be regarded for processes: Timer actions for data groups should, if possible, restrict the number of results via a filter to keep the number of database operations as low as possible, e.g. filter for incomplete tasks, non-archived articles etc. As standard, the setting "Log only warnings and errors" should be activated. If "g_log.info()" is inserted for the purpose of debugging, This can be kept in the code and is ignored during regular use, and thus the log files are kept small.