Tips & Tricks - Import XML via data transfer
Seeing as XML files can have a variety of structures, you cannot get around having to write an individual import script every time you import an XML file. Intrexx provides you with the ability to use a corresponding Groovy script as a data source when using Data transfer.
Analyzing the XML structure

For this example, the export of a basic application containing simple sample data is used. The data contained will be exported as well. To do this, the setting "Export with application data" is set during the export.
![]()
Unpack the exported ZIP file. Change the extension ".lax" of the application export that is included to ".zip" and unzip this file as well.
![]()
You will then find a folder with the GUID of the application.
![]()
This folder contains the "data" folder, in which you will find the data of the application as an XML.
The XML files have the same name as the data groups in the application from which the data originates (e.g. "IX_BASIC_DATAGROUP.data"). The XML file's structure looks something like this:
<dump>
<schema>
...
</schema>
<data>
<r>
<c n="data-field1-name">1</c>
<c n="data-field2-name">1</c>
<c n="data-field3-name">First entry</c>
</r>
...
</data>
</dump>
An additional <r> element is added for each data record.
Create Groovy script
When configuring the data transfer, the data source and the transformation type must be changed to "Groovy script".
![]()
Click "Next".
![]()
To start with, Intrexx generates a dummy script that is kept general and not specifically intended for XML data. This script just needs to be amended now. Open the Intrexx Editor by clicking on the corresponding link.
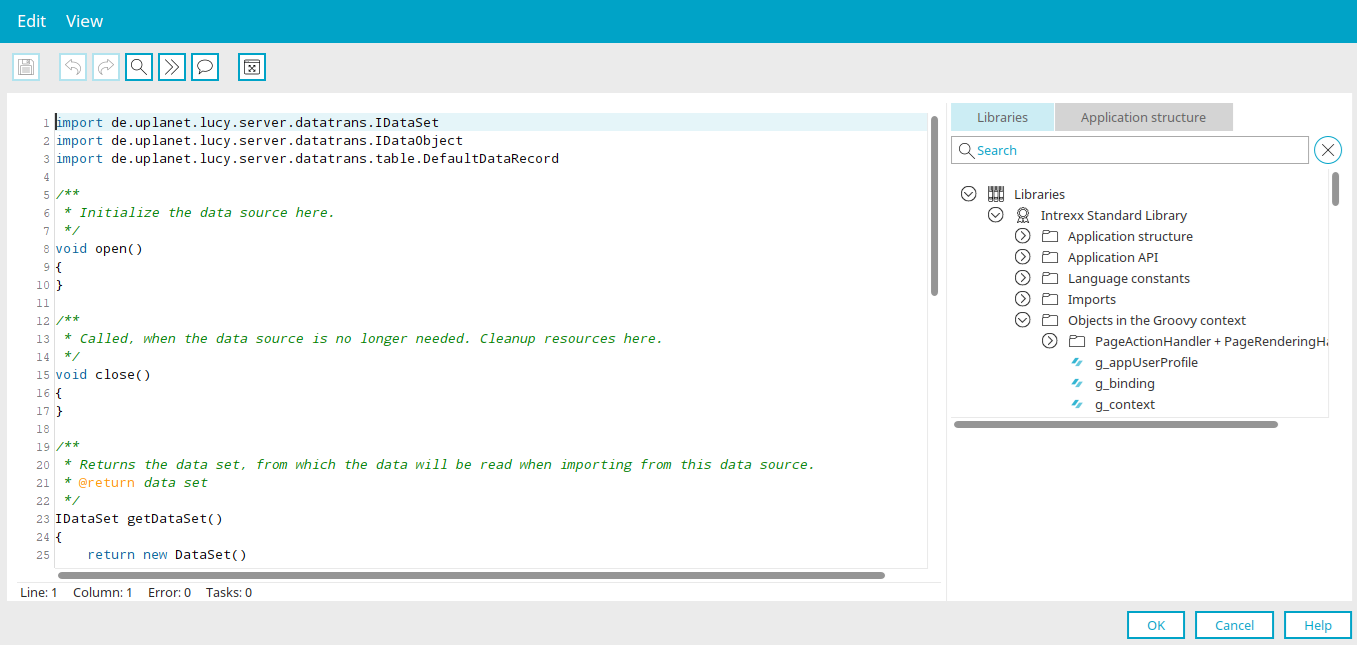
Replace the script that is already present with the one below:
import groovy.xml.XmlParser
import de.uplanet.lucy.server.datatrans.IDataSet
import de.uplanet.lucy.server.datatrans.IDataObject
import de.uplanet.lucy.server.datatrans.table.DefaultDataRecord
import java.text.SimpleDateFormat
import java.util.TimeZone
void open(){}
void close(){}
/**
* Returns the data set, from which the data will be read when importing from this data source.
* @return data set
*/
IDataSet getDataSet()
{
def ds = new DataSet()
ds.parseXML()
return ds
}
/**
* This class is the data source specific data set implementation.
*/
class DataSet implements IDataSet
{
def sdf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'")
def fileContents = new File("C://IX_BASIC_DATAGROUP.data").getText("UTF-8")
def content = new XmlParser().parseText(fileContents)
def xmlRows = content.data.r
def rows = []
def i = 0
void parseXML(){
for(xmlRow in xmlRows)
{
def row = [:]
def xmlColumns = xmlRow.c
for(xmlColumn in xmlColumns)
{
def strColumnName = xmlColumn."@n"
def strValue = xmlColumn.text()
row.put(strColumnName, strValue)
}
rows.add(row)
}
}
IDataObject next(){
if (i >= rows.size()) return null;
sdf.setTimeZone(TimeZone.getTimeZone("UTC"))
def l_record = new DefaultDataRecord(null, [
"dtedit":java.sql.Timestamp,
"luserid":java.lang.Integer,
"dtinsert":java.sql.Timestamp,
"luseridinsert":java.lang.Integer,
"strid":java.lang.String,
"str_title":java.lang.String
])
def row = rows[i]
l_record.setValue("dtedit", new java.sql.Timestamp(sdf.parse(row.get("dtedit")).getTime()))
l_record.setValue("luserid", Integer.parseInt(row.get("luserid")))
l_record.setValue("dtinsert", new java.sql.Timestamp(sdf.parse(row.get("dtinsert")).getTime()))
l_record.setValue("luseridinsert", Integer.parseInt(row.get("luseridinsert")))
l_record.setValue("strid", row.get("strid"))
l_record.setValue("str_title", row.get("str_title"))
i++;
return l_record
}
void close(){}
}
In the script, the "parseXML" method is first added to the "DataSet" class, which loads the content into a buffer as text regardless of the actual data type. When creating the data record, it is mandatory that this is also called up in the method "getDataSet" before the generated object can be returned.
Adjust the path containing the XML file ("IX_BASIC_DATAGROUP.data" in this example) accordingly.
Subsequently, the method Next will be adjusted so that the values in the cache are converted to the actually used data type. In this example the correct Java data types can be found in the XML file itself, the data type of each data field is specified in the schema section.
With this method that the XML file is initially loaded to the cache in its entirety and then processed afterwards. This can lead to a buffer overflow when using large files, this is why a more specialized method should be used in this case.
Save the script by clicking "OK" and then click on "Next".
![]()
Select the target for the import and then click on "Next".
![]()
Select the data group that the data should be imported into. Click "Next".
![]()
Finally, the data needs to be transformed. To do that, the setting "Use transaction, if supported" needs to be activated. Click "Next".
![]()
Now the Groovy script for the transformation is still needed. Open the Intrexx Editor.
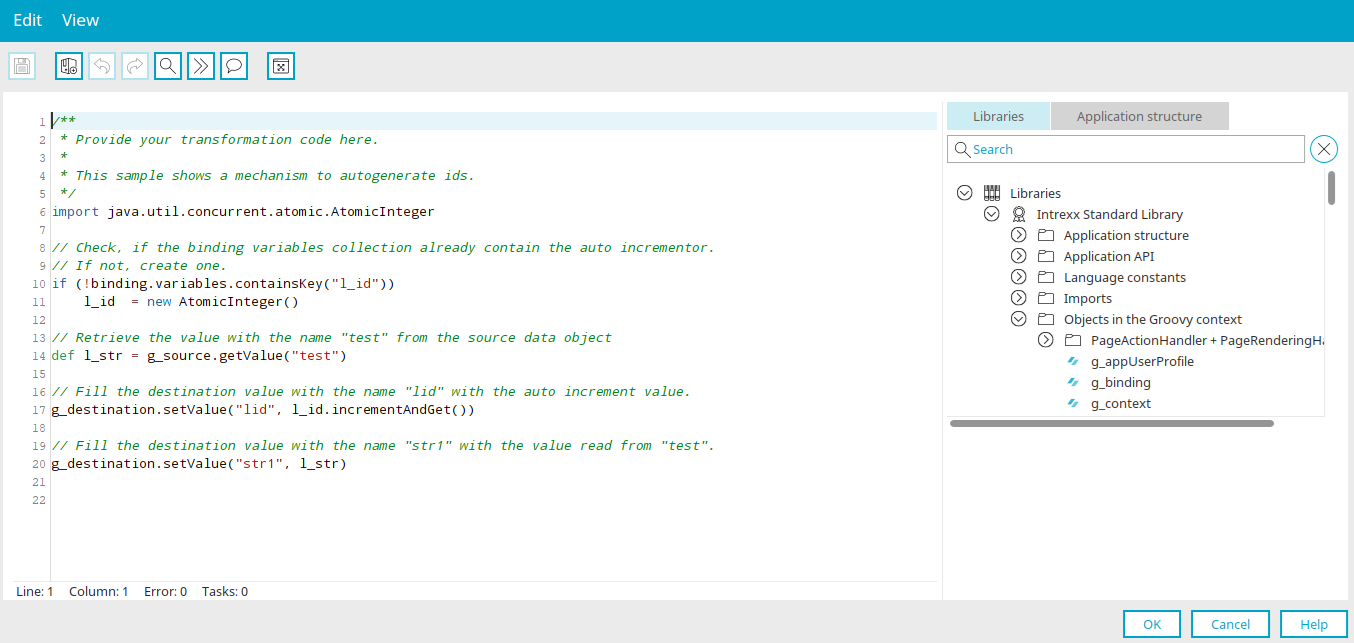
The wizard for creating the data transfer has already adjusted the field for transformation accordingly so that a Groovy script can now be specified here as well. The transformation assigns data fields from the source to the data fields in the target. If you require your own IDs for the import, then this is point when these should be generated and assigned to the ID field.
This is not necessary in this example. The source and target fields can simply be assigned accordingly. Replace the script that is already present with the one below:
g_destination.setValue("dtedit", g_source.getValue("dtedit"))
g_destination.setValue("luserid", g_source.getValue("luserid"))
g_destination.setValue("dtinsert", g_source.getValue("dtinsert"))
g_destination.setValue("luseridinsert", g_source.getValue("luseridinsert"))
g_destination.setValue("strid", g_source.getValue("strid"))
g_destination.setValue("str_title", g_source.getValue("str_title"))
Please check the case sensitivity in the Groovy script if data is not transferred. Depending on the server type, case sensitivity may need to be considered in the formulation of both the source and the transformation.